
The first part of my work on the Contracts dataset can be found here.
You can find the code I used for this section here (same repo as the first part).
Following up on the contracts dataset, I decided to dig a little bit deeper. I was curious to know what sort of contracts the city might be awarding on a regular basis. Though I think I could have figured it out just by looking around (its construction isn’t it?).
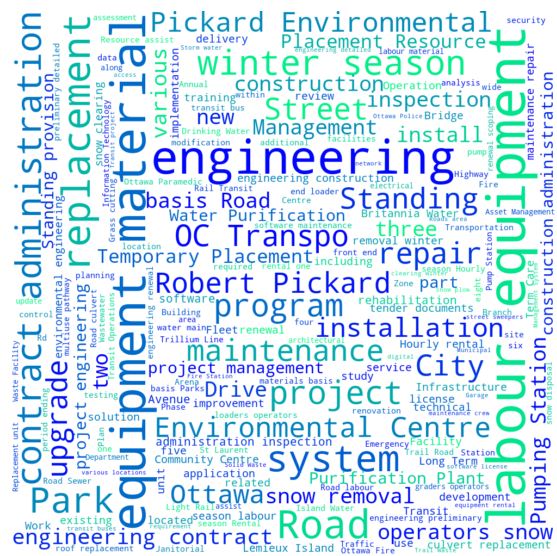
Something like that.
This word Cloud was built using a neat little Python library called WordCloud. I have only made use of the most basic features here, but feel free to play around with it on your own.
To build this Word Cloud, I also used the NLTK library (Natural Language Toolkit).
Basically, the data I had was a series of text strings. Using the tokenization process, I turned that bunch of strings into an unstructured series of strings. Punctuation was removed, and “Stopwords” (words that will have little meaning like an or the), were also removed.
To break my text down further, I was also able to add my own stopwords, words which I felt told me nothing in the analysis. I ran a few iterations through, just to clear some of the larger words that did not mean much to my current analysis.
Finally, I turned the text into one long run-on sentence, and then separated this into its most common n-grams.
Turning text into n-grams involves getting all instances of n words of text. For bigrams, that means all possible two-word groups. By counting these, we can potentially isolate some more common meanings throughout the text we are analysing.

Common grams, or the most common words left

Common bigrams
If we take a look at the counts of single words, and compare them to the most common bigrams, we can definitely see the difference between the information you can glean from judicious use of n-grams.

Common trigrams
Wow, fascinating diagrams.
I know, I know.
When we look at some of the most common trigrams, we can see that, in some cases, we can gain more information, and in others, not so much. It is up to us to analyse and determine strategies for getting the most out of this data. Unfortunately, text analysis may not lead us to exciting graphs and charts right away.
This type of text analysis is often pre-processing for something like sentiment analysis. Here's an interesting paper on the subject.
Sentiment analysis is an incredibly useful tool for fields like marketing and politics, amongst many others. For a second look at this data, "sentiment" analysis could be used to classify different contracts into categories (obviously they are not sentiments, but the principle remains the same).
In any case, what I have found from this simple analysis is that, yes indeed, construction is one of the most common types of contracts awarded. Beside that, there is a lot of ongoing maintenance, for the physical systems that make up our city.
What are our takeaways?
I think the biggest thing to note is that engineers are in high-demand for city contracts. So, the city is definitely blessed to have so many institutions for higher-learning, all of which have such highly-rated engineering programs.
Really though, I think this list brings into perspective for me just how much is going on around us, all the time, to keep a city running. To make sure we have clean water, electricity, smooth roads, an LRT system, snow-free roads / sidewalks / bike lanes, it takes a lot of effort.
Sure, its not perfect, and we should always hold our city to the highest standards. But let’s also keep in mind, the fact that it runs as smoothly as it currently does is seriously impressive. Three cheers for those who make it happen!